The following is a practical analysis of the use of BGP in the DC on Arista platforms based largely on Petr Lapukhov's work with BGP in hyperscale DCs
Why Layer 3 (L3)?
Extension of L2
Why BGP?
- Less complexity in protocol design
- Relies on TCP rather than adjacency formation/maintenance and/or flow control
- Less “chatty”
- Supports third-party (recursively-resolved) next-hops
- With proper ASN usage, built-in loop prevention via AS_PATH
- Better support for traffic engineering
General Operations Within the Fabric
ASN Scheme Option 1(Per-Rack Leaf AS)
Below is a diagram derived mostly from an IETF Draft that is a joint effort by Facebook, Google, and Arista Networks for very large data centers. It is shown in entirety to help visualize the reuse of ASNs at the leaf layer.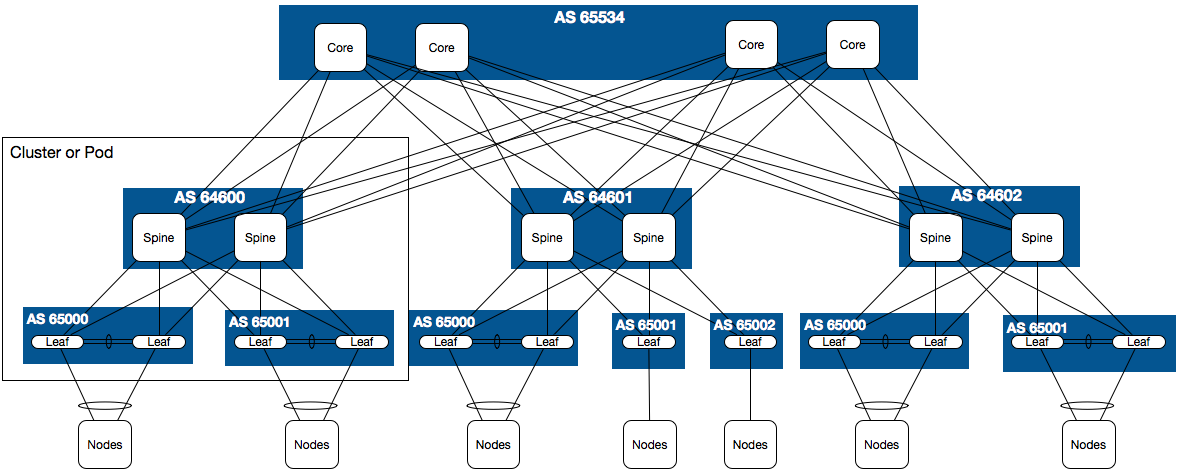
Going forward, focus will be on the spine/leaf elements.
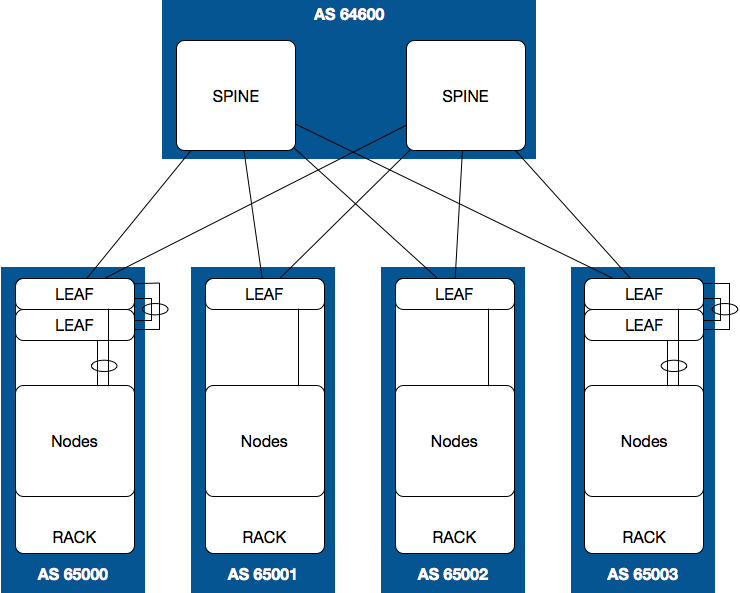
ASN Scheme Option 2 (Leaf Layer AS)
Another option could be to use the same AS at every leaf:
Advantages of this design include less ASN usage, simple configuration templatization, and with that, better support for automation. A disadvantage is losing the ability to trace routes via AS_PATH (At least without additional configuration). These topics are further discussed in later sections.
Intra-AS Spine-to-Spine Reachability
Due to the spine switches being in the same AS, direct reachability from spine-to-spine within the same AS is not supportable without breaking loop prevention within the architecture itself. However, the impact of this is very minimal and should mostly be ignored.
Dynamic Neighbor Discovery
BGP Dynamic Neighbors with Per-Rack Leaf AS
Below is a diagram depicting the utilization of a separate AS at each rack: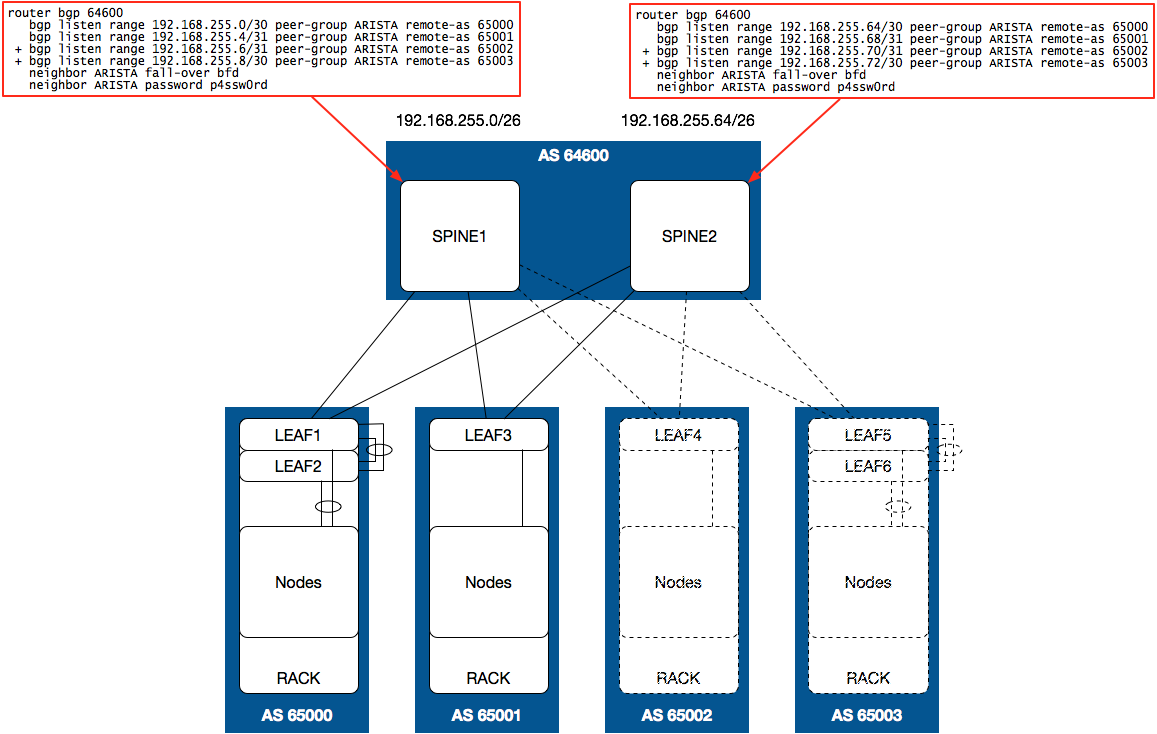
In this configuration, a bgp listen router configuration command is added for each new rack with the IP address range accounting for the routed links going to each leaf switch within the rack. This reduces the amount of required configuration versus static configuration for each individual leaf.
BGP Dynamic Neighbors with Leaf Layer AS
Below, the second option leverages the same AS at every leaf: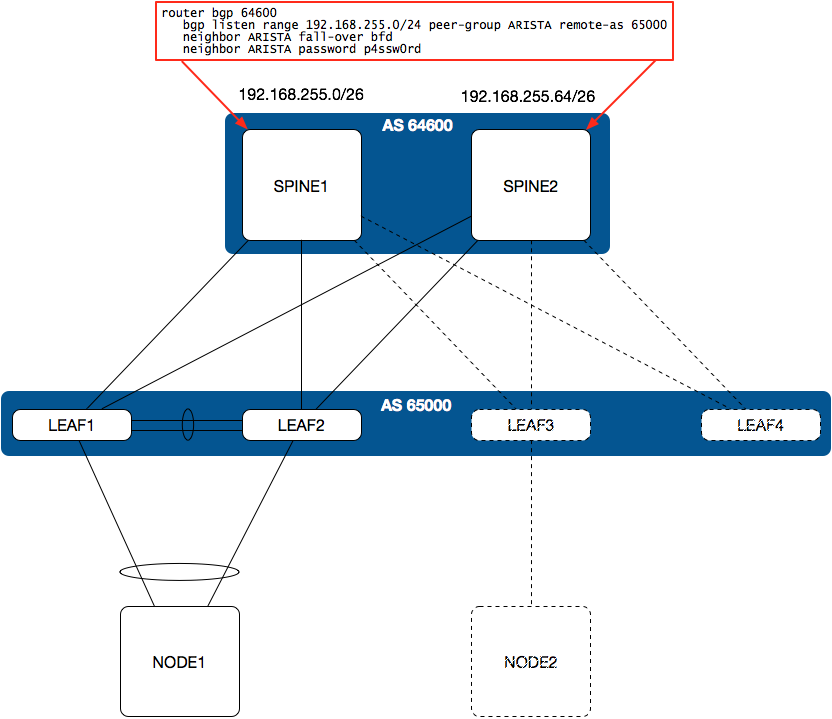
In this configuration, a single bgp listen router configuration command is all that is required at each spine. No further configuration is needed at the spine as additional leaf switches are added to the environment. This makes the configuration easy to templatize and automate across all spine switches.
Making it Easy to Automate
For example, Ansible is a YAML-based automation platform that can be leveraged to push configuration to Arista switches. When configuration is simple and repeatable on as many devices as possible, that configuration can be compartmentalized into a template more easily. Ansible uses “playbooks” which are basically a list of resources and what tasks should be performed on those resources. Below is an excerpt from a playbook showing a single template configuration that could be applied to all spine switches in a per-rack Leaf AS design (Given a whopping two racks, but you get the idea):
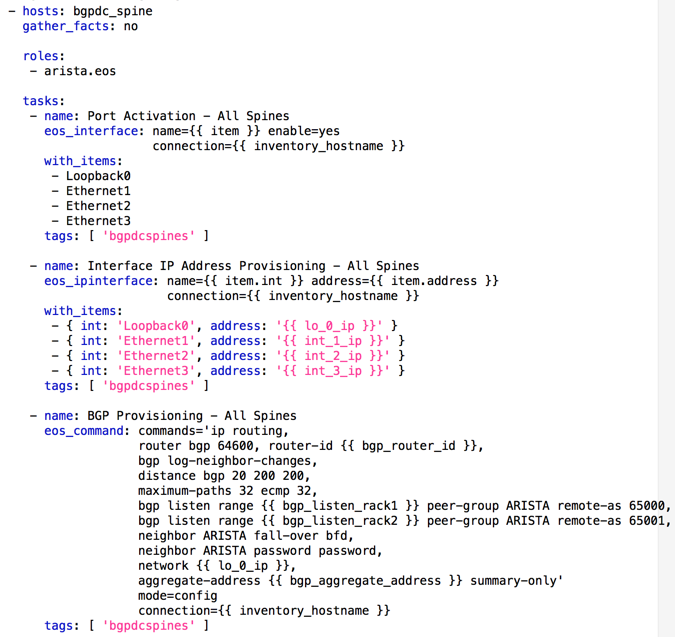
In summary, the more configuration you can compartmentalize and template, the less items need to be defined as variables while still being able to be repeated on multiple devices - and still meet requirements of course - the better.
Route Source Tracing via AS_PATH with Leaf Layer AS
As mentioned earlier, a disadvantage to using the same AS at every leaf is not having the ability to trace routes via AS_PATH:
To get around this, an ASN could be prepended using a route map on each leaf switch, for example:
BGPDC-LEAF1(config)#route-map BGP_PREPEND
BGPDC-LEAF1(config-route-map-BGP_PREPEND)#set as-path prepend 65101
BGPDC-LEAF2(config)#route-map BGP_PREPEND
BGPDC-LEAF2(config-route-map-BGP_PREPEND)#set as-path prepend 65102
Then on both leaf switches, apply the route-map to all advertised routes:
router bgp 65000
neighbor ARISTA route-map BGP_PREPEND out
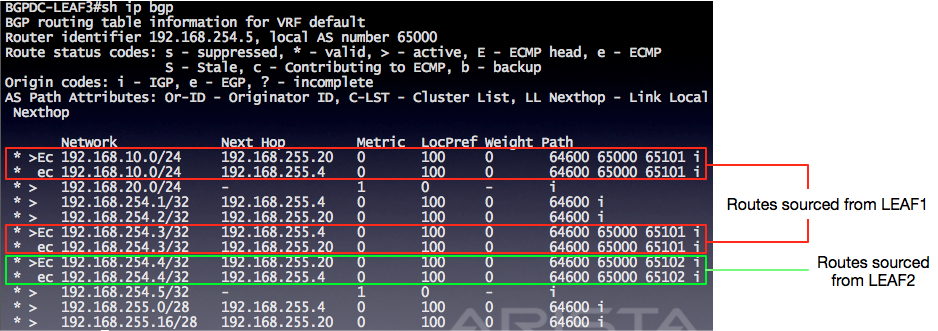
Now from LEAF3’s perspective, it is easier to see where the routes were sourced from:
IP Addressing and Prefix Advertisement
As a hypothetical example, if an Arista 7050QX-32 switch were to be used as a spine switch, assuming no ports are used for uplinks to the core or edge, and only 40Gb links are used to connect leaf switches, you would have a total of 32 links with /31 addressing. This means they could be aggregated as follows:
- 16 /30s
- 8 /29s
- 4 /28s
- 2 /27s
- 1 /26
What this will ultimately look like from the leaf layer perspective is an optimized RIB containing the loopbacks of all switches in the fabric, and a single additional entry per spine switch to reach point-to-point IP addresses for troubleshooting purposes.
To help visualize, consider a scenario where two spine switches are connected to just three leaf switches. The two spine switches have been configured to advertise every leaf connection, like so:
BGPDC-SPINE1(config-router-bgp)#sh active
router bgp 64600
router-id 192.168.254.1
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
bgp listen range 192.168.255.0/24 peer-group ARISTA remote-as 65000
neighbor ARISTA peer-group
neighbor ARISTA fall-over bfd
neighbor ARISTA password 7 6x5GIQqJNWigZDc2QCgeMg==
neighbor ARISTA maximum-routes 12000
network 192.168.254.1/32
network 192.168.255.0/31
network 192.168.255.2/31
network 192.168.255.4/31
Looking at the routing table of LEAF1, there are a number of /31 entries learned via BGP:
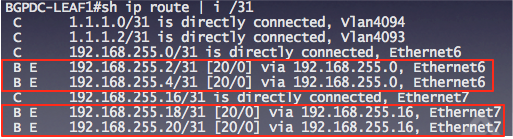
As you can imagine, in larger environments, the number of entries could be excessive. Instead, the spine switches can configured with the aggregate-address router configuration command:
BGPDC-SPINE1(config-router-bgp)#sh active
router bgp 64600
router-id 192.168.254.1
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
bgp listen range 192.168.255.0/24 peer-group ARISTA remote-as 65000
neighbor ARISTA peer-group
neighbor ARISTA fall-over bfd
neighbor ARISTA password 7 6x5GIQqJNWigZDc2QCgeMg==
neighbor ARISTA maximum-routes 12000
network 192.168.254.1/32
aggregate-address 192.168.255.0/28 summary-only
The same output from LEAF1 now shows no /31 entries learned from BGP:

Instead, there is a single /28 entry from each spine learned via BGP:

BGP at the Spine Layer
The Need for Fast Failure Detection
In a BGP switch fabric it is critical for failures to be detected as quickly as possible at the spine layer. Consider the following hypothetical scenario: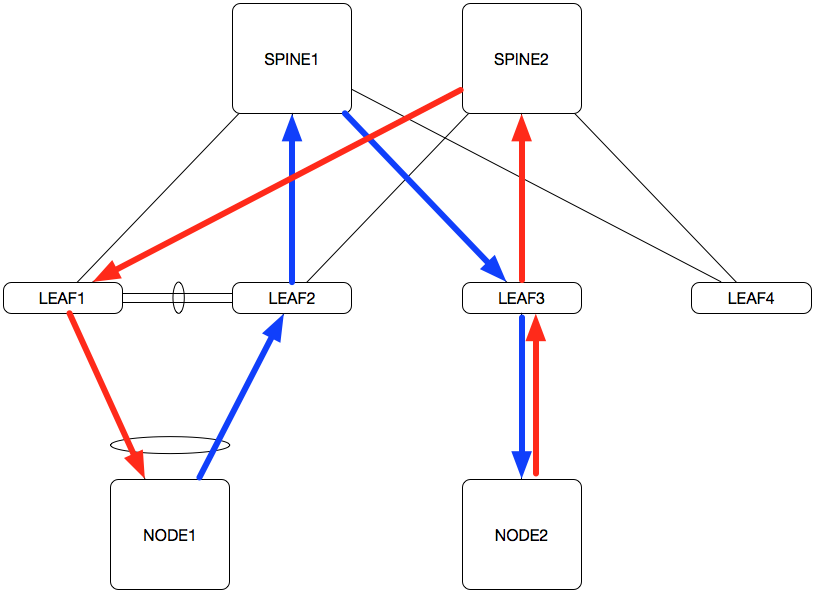
NODE1 is communicating with NODE2. LEAF1 and LEAF2 are MLAG peers. In an ECMP-routed switch fabric, asymmetric routing can occur, where NODE1’s traffic flow is taking the path through LEAF2, while the return traffic is taking the path through LEAF1. This is fine for now, but let’s consider what happens when LEAF1 is rebooted:

With default behavior of MLAG, when LEAF1 finishes rebooting and re-establishes the MLAG session with LEAF2, LEAF1 will place all non-peer-link interfaces into the err-disable state for 300 seconds (five minutes) in order to allow the topology to reconverge. So including the reboot, you’re looking at ~7 minutes or so before the switch begins forwarding again. Even though you have a redundant gateway provided by LEAF2, the reboot of LEAF1 would actually create a problem when combined with the fact that the spine switches are using default configuration in this particular situation of asymmetric routing. Default BGP keepalive and hold timers are 30 seconds and 180 seconds, respectively, so for 180 seconds (3 minutes), the spine switches will still consider LEAF1 an established BGP neighbor, and still consider the path to LEAF1 a viable route even though it’s clearly not. So for any flow that gets hashed to this path, the traffic is effectively blackholed. BGP timers could be modified to provide some relief, but failover time may still be considered unacceptable, in addition to the possibility of introducing instability of the network to BGP peer flapping.
By default, Arista switches will immediately tear down an eBGP neighbor adjacency when the interconnecting link goes down. This alleviates the issue described above. To further improve failure detection, Bidirectional Forwarding Detection (BFD) should also be leveraged. BFD is a very simple, low overhead Hello protocol that works in conjunction with BGP to provide sub-second failure detection. BFD adds additional protection in “gray” failure conditions such as would possibly be seen with a degraded fiber strand. The interface status may remain up and therefore not trigger the eBGP neighborship tear-down, but not pass traffic intermittently or at all - which in those cases network performance can suffer while the BGP keepalive/hold-down mechanism by itself may or may not be of much help.
BGP at the Leaf Layer
MLAG - To Peer or not to Peer
When running a pair of leaf switches in an MLAG configuration with VARP, you want to peer the two leaf switches. Although unlikely to actually happen, consider the following failure scenario: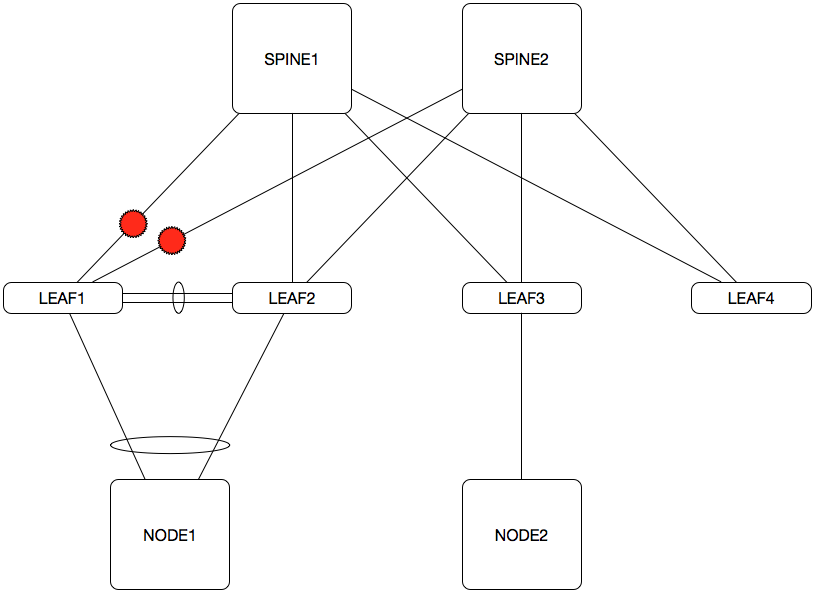
NODE1 is communicating with NODE2. LEAF1 and LEAF2 are MLAG peers and are configured to run VARP to provide an active/active redundant first hop gateway for NODE1, but they are not BGP peers. On LEAF1, both of its uplinks have failed. While both SPINE1 and SPINE2 would certainly notice this failure and reconverge, some things will not be affected, such as:
- MLAG running between LEAF1 and LEAF2 would not notice any change, and continue functioning as normal, which in turn means that the port-channel between NODE1 and LEAF1/LEAF2 would remain up and function as normal
- VARP would continue to function as normal

Peering LEAF1 and LEAF2 alleviates this. Traffic hashed to LEAF1 would follow the only remaining route pointing to LEAF2, and then be ECMP-routed to the spine layer:
Additionally, when this failure scenario doesn’t exist, you don’t have to worry about having a suboptimal path because without the failure described above, the path through the peering leaf switch is longer than those directly connected to the spine layer:

Optimizations
update wait-for-convergence
The update wait-for-convergence BGP router configuration command basically prevents BGP from programming routes into hardware and from advertising routes until a convergence event is resolved. A convergence event can occur when initializing BGP for the first time, clearing the BGP process, terminating the Rib agent, etc. The benefit this provides is reduced CPU churn from repeatedly programming routes into and out of hardware during a convergence event.Best practice is to only use this on spine switches. Enabling this on leaf switches (especially leaf switches acting as host gateways) can result in traffic being blackholed until BGP finishes installing routes in hardware.
NOTE: Enabling this feature in vEOS will cause routes not to be advertised.
update wait-install
The update wait-install BGP router configuration command prevents routes from being advertised to peers until they are programmed in hardware, and that hardware sends an “Ack” to software. This prevents traffic being dropped in situations where routes are advertised, but they aren’t programmed yet in hardware.NOTE: Enabling this feature in vEOS will cause routes not to be advertised.
ip hardware fib next-hop update event bfd
The ip hardware fib next-hop update event bfd global configuration command allows BFD to remove an interface that went down from next-hop entries of routes using it in hardware. The benefit is reduced traffic loss compared to the normal operation of BFD which is to bring down the BGP neighborship and recompute the next-hop for all routes using the interface which went down and then reprogram hardware. This is a default configuration whenever BFD is enabled.ip hardware fib route unprogrammed parent-drop
The ip hardware fib route unprogrammed parent-drop global configuration command makes it so that if a more specific route cannot be programmed in hardware for whatever reason, its parent route will be programmed to point to a drop index (similar to null0). This is default behavior.
NOTE: This is not really an optimization, and is instead more of a feature. It should be noted that this will result in traffic being black-holed rather than being forwarded on to possibly undesirable destinations which is the “benefit” of this feature. An unfortunate side effect is that if there is no other parent route, the default route will be pointed to a drop index instead. In summary, if there isn’t a need to prevent traffic being routed using parent routes when a more specific route cannot be programmed, it is recommended to disable this feature with the “no” form of the same command.
Sources
- RFC 4271, “A Border Gateway Protocol 4 (BGP-4)”, https://tools.ietf.org/html/rfc4271
- “Use of BGP for routing in large-scale data centers”, http://datatracker.ietf.org/doc/draft-ietf-rtgwg-bgp-routing-large-dc/
- “Understanding BGP Convergence”, http://blog.ine.com/2010/11/22/understanding-bgp-convergence/
Configuration Excerpt Examples
Per-Rack Leaf AS (Option 1)
SPINE1
interface Ethernet1no switchport
ip address 192.168.255.0/31
!
interface Ethernet2
no switchport
ip address 192.168.255.2/31
!
interface Ethernet3
no switchport
ip address 192.168.255.4/31
!
interface Loopback0
ip address 192.168.254.1/32
!
ip routing
no ip hardware fib route unprogrammed parent-drop
!
router bgp 64600
router-id 192.168.254.1
update wait-for-convergence
update wait-install
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
bgp listen range 192.168.255.0/30 peer-group ARISTA remote-as 65000
bgp listen range 192.168.255.4/31 peer-group ARISTA remote-as 65001
neighbor ARISTA peer-group
neighbor ARISTA fall-over bfd
neighbor ARISTA password p4ssw0rd
network 192.168.254.1/32
aggregate-address 192.168.255.0/28 summary-only
LEAF1
vlan 10name HOST_10
!
vlan 4093
name BGP_PEER
trunk group BGP_PEER
!
vlan 4094
name MLAG
trunk group MLAG
!
interface Port-Channel1
switchport mode trunk
switchport trunk group BGP_PEER
switchport trunk group MLAG
!
interface Ethernet5
channel-group 1 mode active
!
interface Ethernet6
no switchport
ip address 192.168.255.1/31
!
interface Ethernet7
no switchport
ip address 192.168.255.17/31
!
interface Loopback0
ip address 192.168.254.3/32
!
interface Vlan10
ip address 192.168.10.2/24
ip virtual-router address 192.168.10.1/24
!
interface Vlan4093
ip address 1.1.1.2/31
!
interface Vlan4094
ip address 1.1.1.0/31
!
ip routing
no ip hardware fib route unprogrammed parent-drop
!
!
route-map BGP_PREPEND permit 10
set as-path prepend 65101
!
router bgp 65000
router-id 192.168.254.3
update wait-install
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
neighbor ARISTA peer-group
neighbor ARISTA remote-as 64600
neighbor ARISTA allowas-in 1
neighbor ARISTA fall-over bfd
neighbor ARISTA route-map BGP_PREPEND out
neighbor ARISTA password p4ssw0rd
neighbor 1.1.1.3 peer-group ARISTA
neighbor 1.1.1.3 remote-as 65000
neighbor 1.1.1.3 next-hop-self
neighbor 192.168.255.0 peer-group ARISTA
neighbor 192.168.255.16 peer-group ARISTA
network 192.168.10.0/24
network 192.168.254.3/32
Leaf Layer AS (Option 2)
SPINE1
no switchport
ip address 192.168.255.0/31
!
interface Ethernet2
no switchport
ip address 192.168.255.2/31
!
interface Ethernet3
no switchport
ip address 192.168.255.4/31
!
interface Loopback0
ip address 192.168.254.1/32
!
ip routing
no ip hardware fib route unprogrammed parent-drop
!
router bgp 64600
router-id 192.168.254.1
update wait-for-convergence
update wait-install
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
bgp listen range 192.168.255.0/24 peer-group ARISTA remote-as 65000
neighbor ARISTA peer-group
neighbor ARISTA fall-over bfd
neighbor ARISTA password p4ssw0rd
neighbor ARISTA maximum-routes 12000
network 192.168.254.1/32
aggregate-address 192.168.255.0/28 summary-only
LEAF1
vlan 10name HOST_10
!
vlan 4093
name BGP_PEER
trunk group BGP_PEER
!
interface Port-Channel1
switchport mode trunk
switchport trunk group BGP_PEER
switchport trunk group MLAG
!
interface Ethernet5
channel-group 1 mode active
!
interface Ethernet6
no switchport
ip address 192.168.255.1/31
!
interface Ethernet7
no switchport
ip address 192.168.255.17/31
!
interface Loopback0
ip address 192.168.254.3/32
!
interface Vlan10
ip address 192.168.10.2/24
ip virtual-router address 192.168.10.1
!
interface Vlan4093
ip address 1.1.1.2/31
!
ip routing
no ip hardware fib route unprogrammed parent-drop
!
route-map BGP_PREPEND permit 10
set as-path prepend 65101
!
router bgp 65000
router-id 192.168.254.3
update wait-install
bgp log-neighbor-changes
distance bgp 20 200 200
maximum-paths 32 ecmp 32
neighbor ARISTA peer-group
neighbor ARISTA remote-as 64600
neighbor ARISTA allowas-in 1
neighbor ARISTA fall-over bfd
neighbor ARISTA route-map BGP_PREPEND out
neighbor ARISTA password p4ssw0rd
neighbor 1.1.1.3 peer-group ARISTA
neighbor 1.1.1.3 remote-as 65000
neighbor 1.1.1.3 next-hop-self
neighbor 192.168.255.0 peer-group ARISTA
neighbor 192.168.255.16 peer-group ARISTA
network 192.168.10.0/24
network 192.168.254.3/32